Distributed Training in Pytorch (DDP): Part 1
Idea 🚀
Model training takes a lot of time. If we can distribute the training across multiple machines, we can reduce the training time. Also, many times, a model is too big to fit in a single GPU, so we can parallelize the training across multiple GPUs.
Training a model on multiple machines (nodes) having multiple GPUs is a common practice in deep learning for very large models.
In this blog, we will discuss one of such techniques: Distributed Data Parallel (DDP).
Distributed training
Types of Distributed Training 🚀
There are multiple ways to do distributed training in Pytorch. But, we will discuss two of them:
- Distributed Data Parallel (
DDP) - Fully Sharded Data Parallel (
FSDP)
- Use
DDP, if your model fits in a single GPU but you want to easily scale up training using multiple GPUs. - Use
FSDP, when your model cannot fit on one GPU.
In this blog, we will discuss DDP. Refer to fsdp blog, if you want to learn about FSDP
.
What actually happens in DDP? 🚀
As the word Distributed Data parallel suggests, we are distributing the data parallely across multiple GPUs.
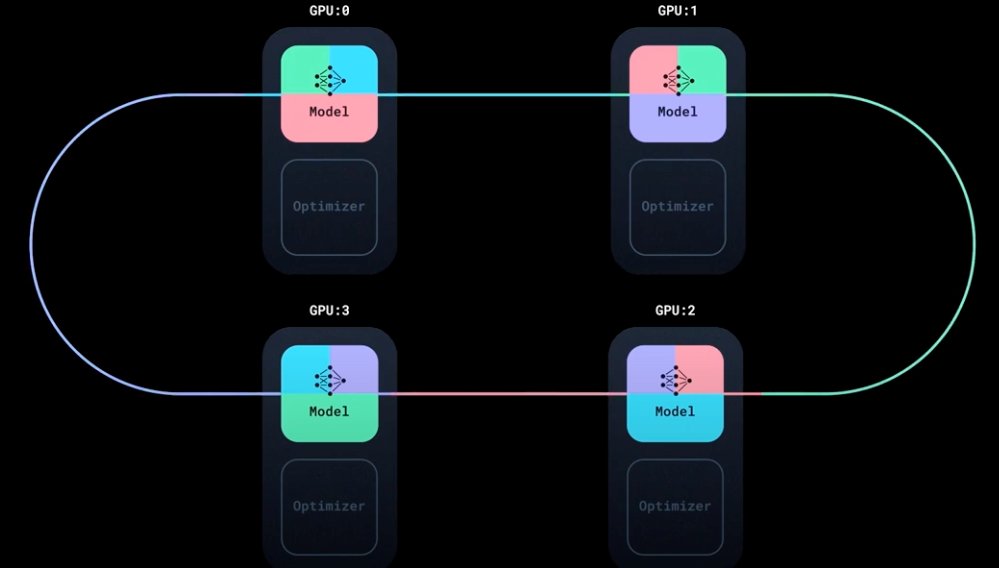
DDP ring-allreduce
In DDP, we have a model and an optimizer. We copy the model across all the GPUs and then we copy the optimizer with same random seed across all the GPUs.
Then, we have a DistributedSampler which is responsible for distributing the data across all the GPUs, and makes sure each GPU gets different data.
Each instance of model (running on different GPU) does the forward pass and backward pass.
Now, all the GPUs have the same model and optimizer, but gradients are different (as they are computed on different data).
We somehow need to average the gradients across all the GPUs and then update the model and optimizer. But, how do we do that?
One possible approach could be to make any one of the GPUs as the master GPU and then all the other GPUs will send their gradients to the master GPU. It will then average the gradients and then send the averaged gradients back to all the GPUs. But, this is not a good approach as it will cause a lot of communication overhead. As we need to send the gradients from all the GPUs to one GPU, and then receive the averaged gradients back from the master GPU. Also, we have to wait till the complete backward pass (gradient computation) is done on all the GPUs, before they can send their gradients to the master GPU.
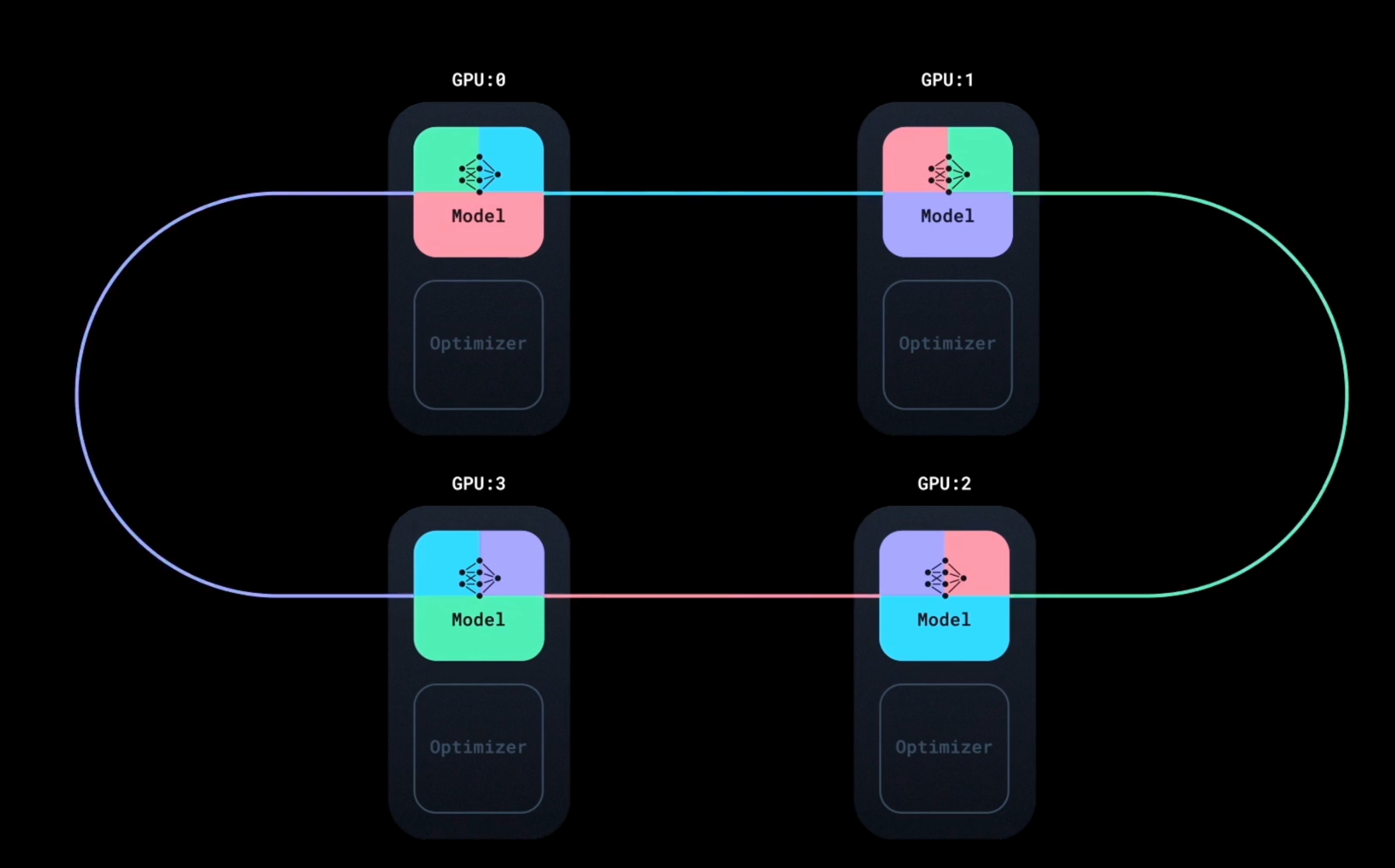
So, the better approach is to use ring-allreduce algorithm. Let’s say, after we have done backward pass for 2 layers, their gradients are ready to be sent to other GPUs. In first round, each GPU will send its gradients to the next GPU. In the second round, each GPU will send gradients that it received from the previous GPU to the next GPU and so on. This will be repeated until all the gradients are sent to all the GPUs.
Now, we have all the gradients on all the GPUs. We didn’t waited for the complete backward pass to be done on all the GPUs. Also, no master GPU is needed. So, we can now average the gradients across all the GPUs and then update the model and optimizer.