Distributed Data Parallel (DDP)
Distributed Data Parallel (DDP)

🧠 Concept: Training Workflows
Single-GPU (No Parallelism)
<p>DataLoader → batch → model → loss → backward → optimizer.step()</p>
- Everything runs in one process, on one device.
DDP
<p>Multiple processes — each with its <strong>own model replica and DataLoader</strong>, running on a <strong>separate GPU</strong>.</p>
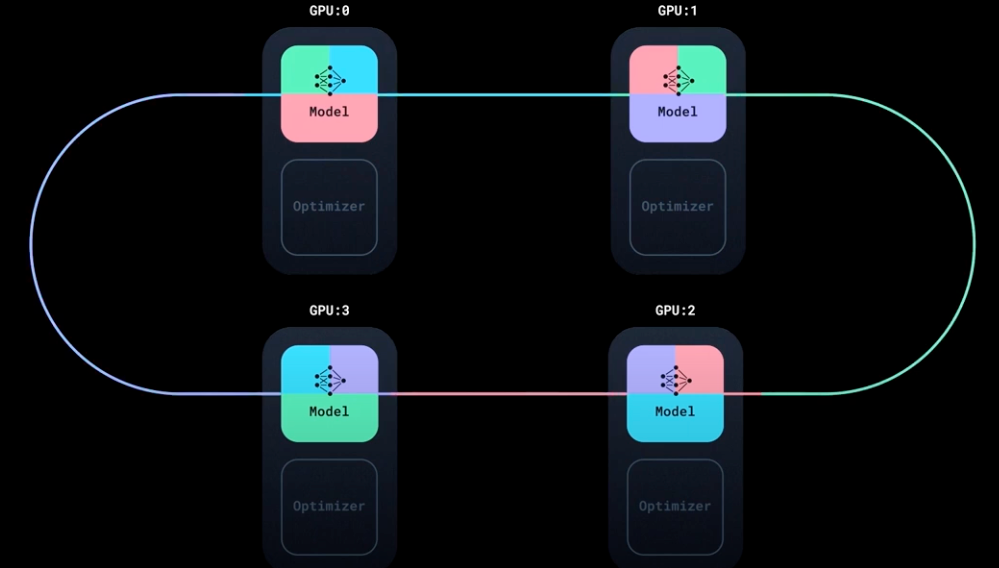
Each process does the following:
- Loads a different subset of data using its own DataLoader (thanks to
DistributedSampler). - Performs forward + backward pass independently on its own model replica.
- During
backward(), gradients are synchronized across all processes usingall-reduce. - Each process computes the average gradient, ensuring consistent updates.
- Each optimizer step updates its local model, but all replicas remain in sync because gradients were averaged.
✅ This gives you data parallelism with minimal communication overhead and no parameter divergence.
DDP over DataParallel (DP)
<p>DataParallel is an <strong>older approach</strong> to data parallelism. DP is trivially simple (with just one extra line of code) but it is much less performant.</p>
DataParallel | DistributedDataParallel |
|---|---|
| More overhead; model is replicated and destroyed at each forward pass | Model is replicated only once |
| Only supports single-node parallelism | Supports scaling to multiple machines |
| Slower; uses multithreading on a single process and runs into Global Interpreter Lock (GIL) contention | Faster (no GIL contention) because it uses multiprocessing |
Last updated on